









Выбор формата данных для работы со списками
Для работы с клонами нам потребуются списки. Также нужно будет определить формат данных. И здесь не всё так просто. В зависимости от выбора того или иного формата будет зависеть сложность работы с данными, в чём скоро убедимся.
Импорт данных или CSV?
В целях упрощения Scratch 3 в нём присутствуют лишь базовые блоки для работы со строками и списками и нет блоков для преобразования строки с разделителями в список и из списка в строку с разделителями. А зачем, если можно импортировать данные в список из файла?
Импортировать можно, но это даст одномерный список, в котором каждый элемент содержит одно значение. Как быть, если нам нужно в одном элементе списка хранить несколько значений, например, в таком формате:
Список 1
Кот1:x=100,y=100,Видимость=1,Костюм=1 Кот2:x=10,y=10 Ширина шага = 10 Переменная цикла = 1 Количество клонов = 10
Для работы с такой структурой потребуются функции, позволяющие получить значение нужного поля и изменить его. Но можно данный формат привести к одномерному:
Список 2
Кот1.x 100 Кот1.y 100 Кот1.Видимость 1 Кот1.Костюм 1 Кот2.x 10 Кот2.y 10 Ширина шага 10 Переменная цикла 1 Количество клонов 10
Преимущество здесь состоит в том, что для работы достаточно имеющихся блоков. Недостаток - неудобно составлять данные в виде списка. Его можно генерировать автоматически, но с многомерными данными удобнее работать в табличном формате, например, в Excel. Ещё один недостаток проявится при необходимости изменять данную структуру - добавлять и удалять из неё элементы. Это делать несложно, но увеличит количество операций. Например, для удаления записей с именем Кот1 из списка 2 потребуется 4 операции поиска и 8 операций удаления вместо одного поиска и одного удаления из списка 1.
Если одномерный список состоит из элементов с одинаковым количеством полей, то количество операций поиска сокращается до 1, а дальше от найденной позиции удаляем 4 элемента:
Кот1.x 100 Кот1.y 100 Кот2.x 10 Кот2.y 10 Кот3.x 0 Кот3.y 0
Если свойств немного и они четко упорядочены, то можно упростить эту структуру данных, убрав ссылки на свойства:
Кот1 100 100 Кот2 10 10 Кот3 0 0
Часто клоны индексируются числами. Совпадение номер клона с индексом списка клонов удобно для работы. Но в списке выше данные о клоне занимают несколько позиций и придётся подкорректировать индексацию:
1 - Кот1 100 100 4 - Кот2 10 10 7 - Кот3 0 0
Следующий индекс клона будет равен последнему + 3. Вместо этого можно использовать имена клонов. Тогда индекс его имени в списке будет совпадать с его номером в названии:
1 - Кот1 2 - Кот2 3 - Кот3
В строку это бьудет выглядеть так:
Кот1,100,100; Кот2,10,10; Кот3,0,0;
Как видите, даже в Scratch 3 есть возможность выбрать разные форматы данных, которые имеют как преимущества, так и недостатки в рамках этой платформы.
Упрощение работы со списками
В одной статье мне попалась на глаза фраза преподавателя о том, что он сразу учит правильно давать имена перемнным. Что это значит? В Scratch 3 мы не даём имена переменным. Мы даём названия полям. Именования переменных в языках программирования происходит согласно определенным правилам и имеет большие ограничения. А для названий полей можно использовать любые символы, которые в ней могут существовать, хоть символ табуляции, хоть символ смайлика. Правильные - это короткие, но понятные названия? Короткие, но непонятные - это на английском языке. Понятные - это длинные на русском. И есть разница в том, содержат названия и данные внутри себя пробел.
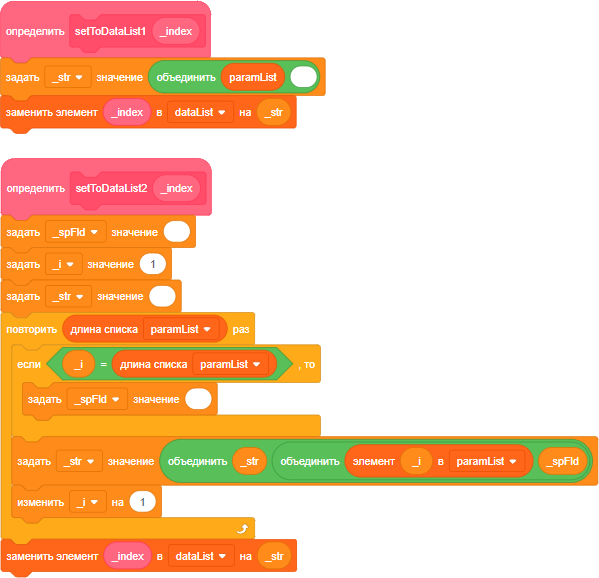
Рис. 1. Вверху разделитель - пробел, внизу разделитель - любой символ.
В этих двух функциях выполняется одно и тоже действие - объединение всех элементов одного списка в строку и вставку её в элемент другого списка. Это нужно, например, для того, чтобы обновить информацию о клоне в списке, если мы решили выбрать вариант, в котором вся информация о клоне находится в одном элементе списка. При преобразовании списка в строку его элементы объединяются при помощи пробела. Если пробел выступает в роли разделителя полей, то его нельзя использовать в именах полей. Если мы хотим объединять поля простым способом, то для этого необходимо структуру данных составлять с учётом двух моментов:
- В именах полей и значениях не должно быть пробелов
- В качестве разделителя полей нужно использовать пробел
Кот1 100 100; - простое объединение Кот 1,100,100; - сложное объединение
Какая из этих записей является более простой для восприятия? Вторая. А какая позволяет упростить работу с блоками? Первая. Вот такой "парадокс".
Многомерные данные удобно составлять в Excel. По после вставки их в текстовой редактор между полями в качестве разделителя появятся символы табуляции. Их можно заменить на пробелы. Но не на обычные, а, например, на неразрывные. Догадались, к чему идёт речь? Пробельных символов существует несколько и можно сделать так, что поля будут разбиваться по символу неразрывного пробела, а в именах и значения полей будут использовать обычные пробелы. Почему так, а не наоборот? Обычный пробел используется чаще, а вводить его проще, чем неразрывный при помощи Alt + 0160 при включенной цифровой клавиатуре.
В последнем случае придётся предварительно заменить символы табуляции на неразрывный пробел. Это немного усложняет процесс и можно пойти другим путём - оставить пробел в качестве разделителя, а в названиях полей и значений вместо него использовать символ подчеркивания.
Блоки упрощают программирование, но отсутсвие нужных блоков его сильно усложняет. Приведу изображение того, что пришлось сделать для того, чтобы реализовать функционал пары блоков для работы с CSV.
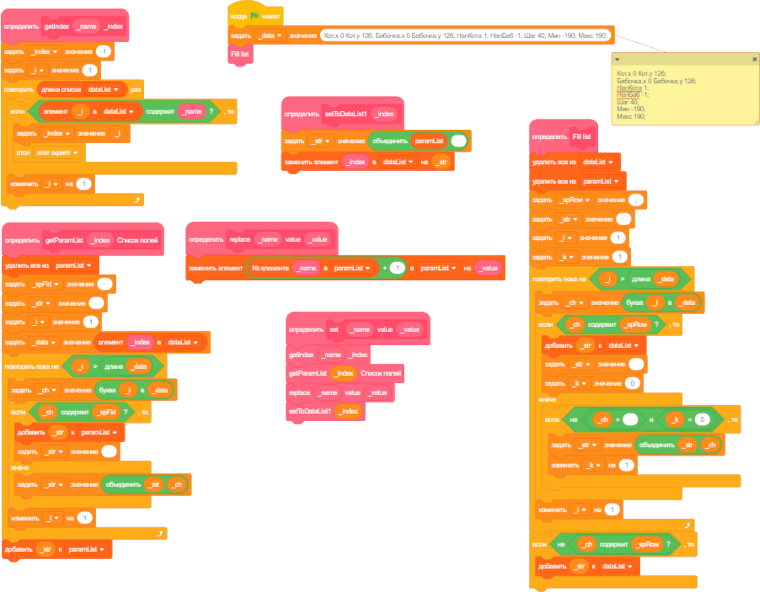
Рис. 2. Когде нет нужных блоков, то приходится делать так.
Если вид блоков не испугал, то можно поиграться с ними в проекте по ссылке