








Оптимизация блоков
Вынос повторяющихся блоков в отдельные функции также можно отнести к оптимизации блоков, но мы поговорим о более тонких моментах, которые позволяют значительно упростить как вид алгоритма, так и дальнейшую работу с его блоками. Попробуем для начала избавиться от "лапши" и "расчёски" в блоке условного оператора.
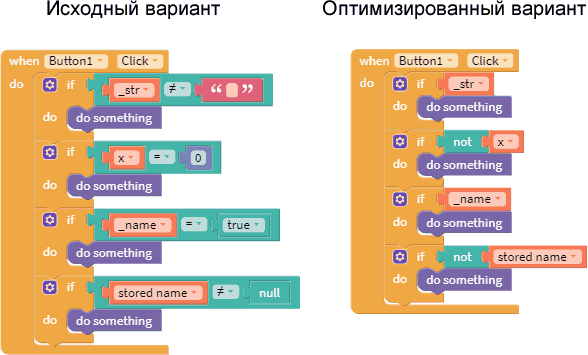
Из JavaScript (который также лежит в основе ядра ThunkableX) известно, что значение false появляется в результате преобразования в логический тип "интуитивно" пустых значений:
- Пустая строка
- 0
- NaN (не число) - результат математической операции или преобразования в число, например:
- "0Test" = 0 (если строка начинается с цифр, то строку можно преобразовать в число)
- "Test" = NaN
- true и false = NaN
- null (нулевое или пустое значение) - несуществующий объект, неинициализированное значение глобальной переменной
- undefined (неопределенная переменная)
В остальных случаях при преобразовании в логический тип будет получено значение true. Отсюда получаем оптимизированные варианты, показанные на рисунке ниже:
- Непустая строка = true
- Равенство 0 = false
- Значение переменной true = значение переменной
- Объект существует = true
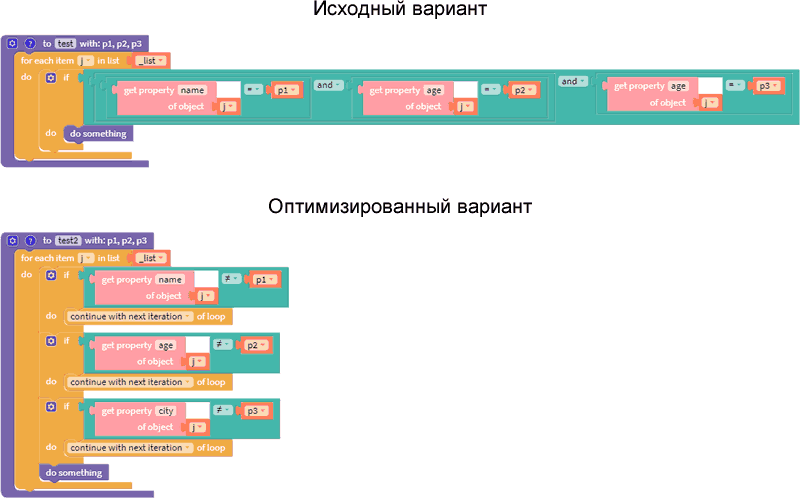
Следующий пример "лапши" возникает при фильтрации значений из списка объектов по нескольким полям. Блоки исходного варианта можно преобразовать к виду с внешним подключением блоков (External Inputs) для их конфигурации по вертикали, но второй вариант и выглядит понятнее, и проще в работе, если возникнет необходимость фильтрации записей по ещё большему количеству полей.
Ниже показан пример многовариантного условного блока, который я называю "расчёской". К сожалению, из-за ограничений возможности блоков, такие конструкции далеко не во всех случаях поддаются полной оптимизации. Если бы название экрана можно было задать при помощи переменной, то показанного кошмара можно было легко избежать. А так возможно лишь разделение одного большого блока "if - else if" на множество отдельных блоков if.

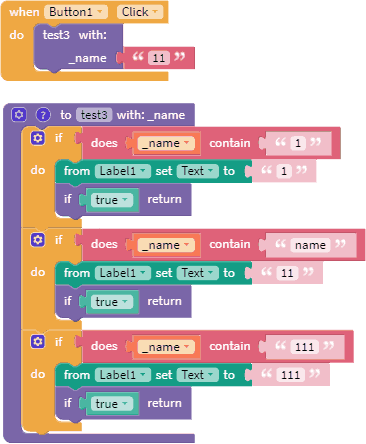
Если алгоритм допускает последовательное срабатывание нескольких блоков if, то это может привести к ошибке, для устранения которой используется блок выхода из функции "if true return". Ниже показаны учебные примеры, которые несложно адаптировать к практическим.
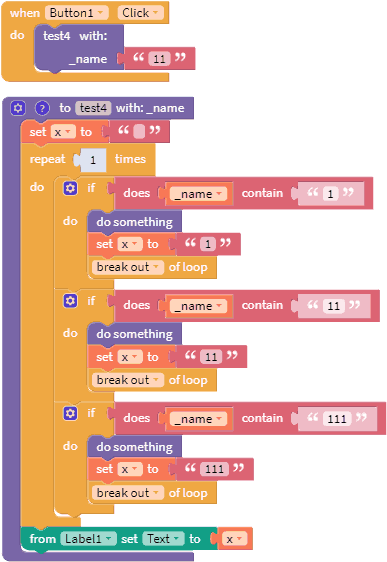
Если после отработки условия нужно выполнить другие блоки функции, то показанную конструкцию необходимо обернуть в блок цикла следующим образом.
Выше были рассмотрены варианты оптимизации блоков, но в некоторых случаях требуется оптимизация на уровне данных: время. Это позволи значительно упростить алгоритм для работы с ними. Типичным примером является разбор данных JSON, что средствами ThunkableX реализовано не в полной мере.
Рассмотрим типовой пример.

Как получить список узлов второго уровня (van1, van2,.van3)? Для этого придётся обратиться к узлу VEHICLES и произвести разбор полученного содержимого при помощи блоков для работы с текстом и списком. А что делать, если эти имена узлов представляют собой идентификаторы, которые на содержат порядковый номер, а сама структура данных является многоуровневой и неоднородной? В таких случаях при создании имён узлов vanN добавьте слева (и/или справа) невидимые символы Юникода. Это позволит ощутимо проще найти все узлы, в именах которых содержится тот или иной невидимые (или уникальный и не используемый в содержимом) символ.