








Оптимизация производительности
После поверхностной оценки производительности работы кода Thunkable X, становится очевидно то, что возможности данной платформы ограничены рамками индивидуального образования. Действительно, достаточно сложно представить себе публичное приложение, которое работает со скоростью создания 100 кнопок за 22 секунды. Разработчики откровенно признались, что над производительностью они как-то не думали, откуда и возникла идея проверить реализацию блока поиска по списку. Вдруг, они решили ограничиться перебором.
Проверить алгоритм работы блока поиска по списку несложно. Для этого возьмём отсортированный список и замерим скорость поиска элементов в разных его частях. Малые расхождения будут говорить об использовании двоичного поиска.
Для теста воспользуемся следующей функцией.
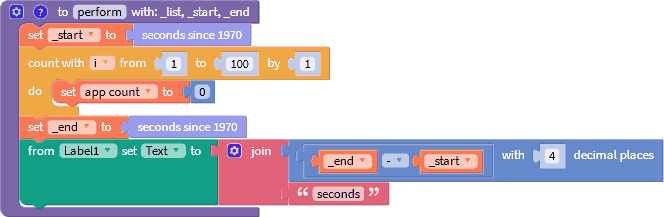
Тестирование происходило на Android 8.1 (MTK6739WA, 4 ядра, 1.3 ГГц) с использованием списка имён, содержащим 20259 записей.
A[2] = 0.0000 cек.
A[100] = 0.001 cек.
A[10360] = 0.001 cек.
A[n]
= 0.002 cек.
Времена поиска элементов близки, что позволяет говорить о реализации двоичного поиска. Для сравнения оценим скорость работы линейного поиска.
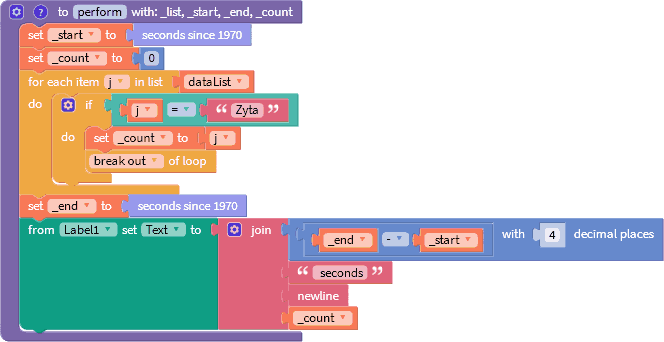
A[n] = 0.1050 сек.
C учётом погрешности измерений можно сказать, что в среднем поиск с использованием встроенного блока в несколько десятков раз быстрее поиска перебором.
Позвольте, но это же самый медленный цикл. Заменим его на самый быстрый.
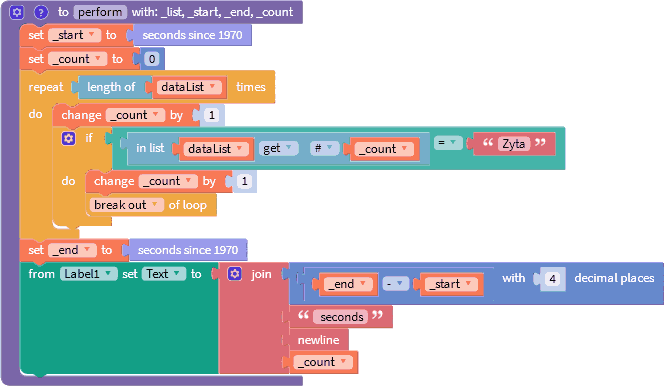
A[n] = 0.045 сек.
Быстрее более чем в 2 раза. Можно ли сказать, что цикл repeat работает в 2 раза быстрее for each? Нет, так как время выполнения циклов зависит от размера входных данных. Из показанного примера с уверенностью можно говорить о том, что цикл repeat работает быстрее for each.
А как обстоит дело с поиском произвольной строки в элементах списка? А вот здесь возникает любопытный момент, касающийся того, что поиск по списку работает в несколько раз медленнее поиска подстрок в списке с разделителями. Это связано с невысокой скоростью работы блока списка получения элемента по индексу. Однако, на практике это никак не отразится на скорости работы приложений Thukable X, так как из-за крайне низкой общей производительности нет никакой разницы между тем, происходит поиск за 0.05 секунды или за 0.22 секунды (если речь не идёт о нескольких сотен тысяч записей).